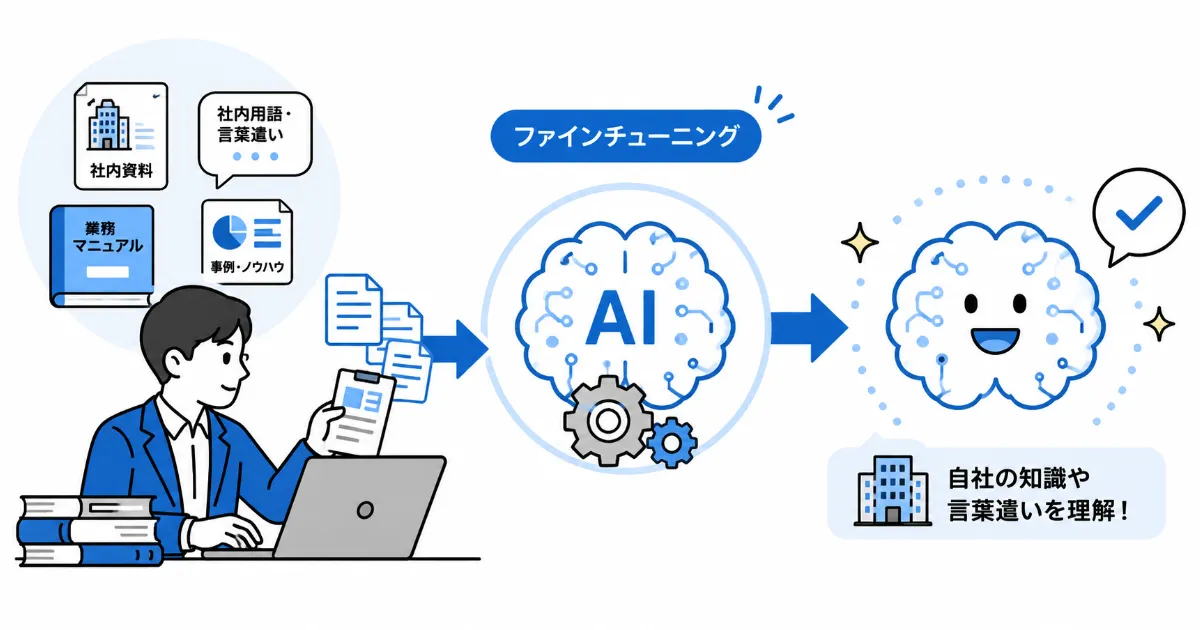
ファインチューニング(追加学習)
既存のAIモデルに特定のデータを用いて追加学習を行い、専門分野の知識や自社独自の文体・トーンを習得させる技術「ファインチューニング」を解説します。「外部情報を参照させる(RAG)」とは異なる「脳そのものを鍛える」手法のメリットと、導入におけるコストや難易度について学びます。
1. 汎用的な「秀才」を特定の「専門家」に変える
ChatGPTなどの大規模言語モデル(LLM)は、インターネット上の膨大なデータを学習した、いわば「あらゆる分野に精通した秀才」です。日常的な会話からプログラミング、一般的なビジネス文書の作成まで、幅広いタスクをこなすことができます。
しかし、特定の企業の内部だけで使われる専門用語や、その企業独特の言い回し、あるいは非常にニッチな業界の専門知識となると、汎用的なAIでは対応しきれない場面が出てきます。
そこで、すでに完成しているAIモデル(プリトレーニング済みモデル)を土台にして、特定のデータセットを使ってさらに「追加の訓練」を行い、特定のタスクや分野に特化させる手法が「ファインチューニング(Fine-tuning)」です。これは、大学を卒業したばかりの優秀な新人に、自社独自の「専門教育」を施してプロフェッショナルに育てるプロセスに似ています。
2. 「辞書を引く(RAG)」か「脳を鍛える(ファインチューニング)」か
AIを自社仕様にカスタマイズする手法として、よく比較されるのが「RAG(検索拡張生成)」です。この2つの違いを正しく理解することは、企業のAI戦略において極めて重要です。
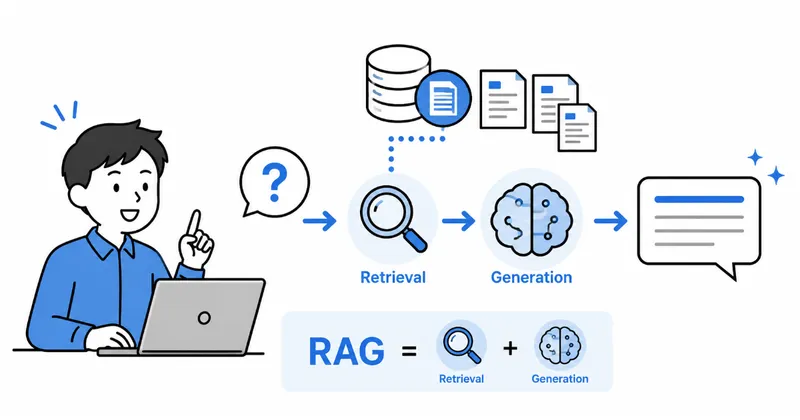
前回の解説で触れた通り、RAGは「AIに参考書や辞書(外部データベース)を渡し、それを見ながら答えさせる」仕組みです。 一方、ファインチューニングは「AIの脳(内部のパラメータ)そのものを書き換え、知識やスキルを定着させる」仕組みです。
- RAGのイメージ: オープンブックの試験(辞書を持ち込んで、調べながら回答する)。最新の事実や数値、頻繁に更新されるマニュアルなどの「事実(ナレッジ)」の扱いに適しています。
- ファインチューニングのイメージ: 猛勉強して知識を頭に叩き込む、あるいは職人の「勘」を養う。特定の「形式(フォーマット)」や「トーン&マナー(語り口)」、あるいは言語そのものの特殊な処理能力を向上させるのに適しています。
3. ファインチューニングが威力を発揮するシーン
実務において、ファインチューニングが必要とされるのは主に以下のようなケースです。
① ブランド独自の「トーン&マナー」の再現
例えば、自社の広報キャラクターらしい独特の話し方や、その企業特有の非常に丁寧な接客メールの文体をAIに完全にマスターさせたい場合、RAGで「お手本」を見せるだけでは限界があります。過去の膨大な接客データを学習させることで、AIの「振る舞い」そのものをブランドイメージに合致させることができます。
② 極めて特殊な専門用語や業界用語の理解
医療、法律、あるいは特定の製造現場など、一般的な辞書には載っていない特殊な用語が飛び交う環境では、汎用AIは言葉の意味を誤解することがあります。ファインチューニングによって専門用語の「文脈」を脳に刻み込むことで、より正確な理解と生成が可能になります。
③ 出力形式(フォーマット)の徹底
「必ずこのJSON形式で出力する」「特定の記号を使って構造化する」といった、厳格な出力ルールを遵守させたい場合、ファインチューニングを行うことで、指示文(プロンプト)で長々と説明しなくても、AIが「それが当たり前」として振る舞うようになります。
4. 導入の壁:コスト、時間、そしてデータの質
RAGと比較して、ファインチューニングは企業にとって「重い」選択肢となることが多いのが現実です。それにはいくつかの理由があります。
- 高品質な「学習データ」の準備: これが最大の難関です。単に資料を放り込めばいいRAGとは異なり、ファインチューニングには「問いと答え」が対になった、正確で整理された大量のデータ(教師データ)が必要です。このデータ作成には、専門知識を持った人間による膨大な手作業が伴います。
- 計算リソースとコスト: AIを再学習させるには、高性能なGPU(グラフィックプロセッサ)を長時間稼働させる必要があり、クラウド利用料などのコストがかさみます。また、一度学習が完了した後に新しい知識を追加したい場合、再び学習をやり直さなければならず、更新の柔軟性に欠けます。
- 「ハルシネーション(嘘)」は消えない: 脳を鍛えても、AIの本質である「確率的な言葉の生成」は変わりません。むしろ、学習させたデータに偏りがあると、特定の答えばかりを返したり、もっともらしい嘘を強化してしまったりするリスクも孕んでいます。
5. どちらを選ぶべきか?現在のトレンドは「RAGファースト」
現在の企業向けAI活用では、「まずはRAGから検討し、どうしても解決できない場合のみファインチューニングを検討する」というアプローチが主流です。
なぜなら、多くのビジネス課題(最新の社内規定に答えさせたい、マニュアルから情報を探したい等)は、RAGの方が「安く、早く、正確に」解決できるからです。ファインチューニングは、「自社のブランド価値を体現するAIを作りたい」といった、より高度で、かつ情報の更新頻度が低い「振る舞い」に関する課題に特化して使われるようになっています。
また、最近では「RAGで最新情報を与えつつ、ファインチューニングで回答の品質やトーンを整える」という、両者のいいとこ取りをしたハイブリッドな構成も増えています。
6. まとめ:AIを「育てる」という覚悟
ファインチューニングは、単なるツールの導入ではなく、AIという知性に自社の「魂(スタイルや専門性)」を吹き込む作業です。
それは、一時的な設定作業ではなく、質の高いデータを継続的に用意し、AIを教育し続けるという、いわば「人事育成」に近い継続的な努力を組織に要求します。
自社がAIに求めているのは「辞書のように正確な知識」なのか、それとも「熟練社員のような独特の勘と文体」なのか。この問いへの答えが、RAGとファインチューニングのどちらを選択すべきかの明快な指針となるでしょう。
この記事の監修者

石崎 一之進
中小企業診断士
年間50回以上のセミナー・研修に登壇する「Web・ITが得意な中小企業診断士」。単なるツール導入ではなく、経営視点から現場の「業務効率化」と「売れる仕組み」づくりを両輪で伴走支援し、企業の自走を促すDX人材育成に力を入れています。「人材開発支援助成金(事業展開等リスキリング支援コース)」活用で最大75%還元されるAI研修も行っています。詳細はAI研修をご覧ください。
参考文献
- OpenAI "Fine-tuning" Documentation https://platform.openai.com/docs/guides/fine-tuning
- Google Cloud "Fine-tuning for LLMs https://cloud.google.com/vertex-ai/docs/generative-ai/models/tune-models