RAG(検索拡張生成)
RAGとは、AIが回答を作る前に社内文書や外部データを検索し、その内容を根拠として回答する仕組みです。基本の流れ、社内文書を使って回答する仕組み、ファインチューニングとの違い、RAGでも残るハルシネーションのリスクを整理します。
この記事でわかること
- RAGの意味と基本の流れ
- 社内文書を使って回答する仕組み
- ファインチューニングとの違い
- RAGでも残るハルシネーションリスク
RAG(検索拡張生成)とは、AIが回答を作る前に、社内文書、マニュアル、FAQ、データベースなどを検索し、見つけた情報を参考にして回答を生成する仕組みです。
通常の生成AIは、学習済みの一般知識だけでは、自社の就業規則、最新の料金表、顧客別の契約条件、昨日更新されたマニュアルには答えられません。RAGは、AIの外側にある情報をその都度検索して渡すことで、回答を業務データに近づけます。
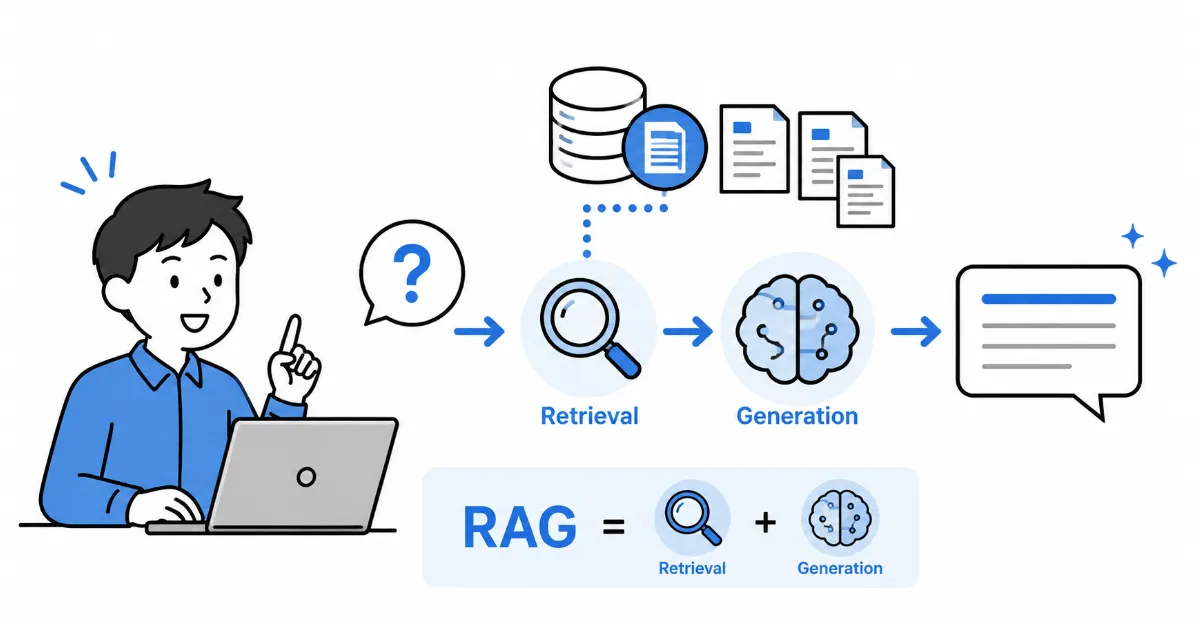
1. RAGは「調べてから答える」仕組み
RAGは「Retrieval-Augmented Generation」の略です。日本語では検索拡張生成と呼ばれます。
言葉を分けると、次のようになります。
- Retrieval: 関連する情報を検索する
- Augmented: 検索した情報をAIへの入力に追加する
- Generation: 追加された情報をもとに回答を生成する
たとえば、社員が「リモートワーク時の交通費精算ルールを教えて」と質問したとします。RAGを使うシステムでは、AIがいきなり答えるのではなく、先に社内規程やFAQを検索し、関連する箇所をAIに渡してから回答を作ります。
2. RAGの基本的な流れ
RAGは、単にPDFをAIに読ませるだけの仕組みではありません。一般的には、次のような流れで動きます。
-
社内文書を取り込む マニュアル、規程、FAQ、議事録などを検索しやすい形に整理します。
-
文書を小さな単位に分ける 長い文書を、見出しや段落ごとの小さなかたまりに分けます。この単位は「チャンク」と呼ばれます。
-
質問に近い情報を検索する ユーザーの質問に対して、関連しそうなチャンクを検索します。ベクトル検索などが使われることもあります。
-
検索結果をAIに渡す AIには、質問だけでなく、検索で見つかった参考情報も一緒に渡します。
-
AIが回答を作る AIは渡された参考情報をもとに、読みやすい文章として回答します。設計によっては、参照元の文書名やリンクも表示できます。
3. RAGでできること
RAGが得意なのは、社内や業界固有の情報を参照しながら、自然な文章で答えることです。
たとえば、次のような用途に向いています。
- 社内規程や業務マニュアルの問い合わせ対応
- 製品資料やFAQをもとにしたカスタマーサポート
- 営業資料、提案書、過去事例の検索補助
- 契約書や仕様書の確認補助
- 社内ナレッジの検索と要約
RAGの価値は、AIが「自社の情報を覚える」ことではありません。必要なときに正しい資料を探し、その資料に基づいて答えられるようにすることです。
4. RAGとファインチューニングの違い
RAGは、AIモデルそのものを追加学習させるファインチューニングとは役割が違います。
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| 目的 | 外部文書を検索して回答に使う | モデルの振る舞いや専門的な出力傾向を調整する |
| 情報更新 | 参照文書を更新すれば反映しやすい | 再学習や再調整が必要になる場合があります |
| 根拠表示 | 参照元を表示しやすい | 出力根拠を直接示すのは苦手です |
| 向いている用途 | 社内FAQ、マニュアル検索、最新情報参照 | 文体調整、分類精度向上、特定タスクへの適応 |
「社内文書を読ませたい」「最新の規程に基づいて答えさせたい」という目的なら、まずRAGを検討するのが自然です。一方で、出力形式や判定傾向を安定させたい場合は、ファインチューニングが選択肢になります。
5. RAGはハルシネーションを減らすが、なくすわけではない
RAGは、AIのハルシネーションを減らす有効な方法です。元のRAG論文でも、事実知識を扱うタスクで、外部の検索結果を使うことの有効性が示されています。
ただし、RAGを入れればAIが必ず正しくなるわけではありません。検索で間違った文書を拾えば、AIはその誤った情報をもとに回答します。検索結果が不足しているのに、AIが補ってしまうこともあります。
失敗しやすいのは、次のような状態です。
- 古い文書と新しい文書が混在している
- ファイル名や見出しが分かりにくく、検索に引っかかりにくい
- PDFの中身が画像化されていて、テキストとして読めない
- 文書の権限管理が整理されていない
- AIに「資料にない場合は分からないと答える」指示が入っていない
- 回答の参照元を人間が確認する運用になっていない
RAGの品質は、AIモデルだけでなく、検索対象となる社内データの品質に強く左右されます。
6. RAGを考える前に整えたいこと
RAGを導入する前に、最初にやるべきことはツール選びではありません。どの文書を正として扱うのかを決めることです。
社内マニュアル、FAQ、規程、商品情報、営業資料などのうち、どれをAIに参照させるのか。古い版をどう扱うのか。誰が更新するのか。誰がどの文書を見てよいのか。ここが曖昧なままだと、RAGは「社内の古い情報をそれらしく答える仕組み」になってしまいます。
RAGは、社内の知識をAIで使いやすくする強力な方法です。しかし本質は、AIの魔法ではなく、社内情報を整理し、検索できる状態にし、根拠を確認しながら使うための設計です。
この記事の監修者

石崎 一之進
中小企業診断士
年間50回以上のセミナー・研修に登壇する「Web・ITが得意な中小企業診断士」。単なるツール導入ではなく、経営視点から現場の「業務効率化」と「売れる仕組み」づくりを両輪で伴走支援し、企業の自走を促すDX人材育成に力を入れています。「人材開発支援助成金(事業展開等リスキリング支援コース)」活用で最大75%還元されるAI研修も行っています。詳細はAI研修をご覧ください。
参考文献
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks https://arxiv.org/abs/2005.11401
- AWS: What is RAG? https://aws.amazon.com/jp/what-is/retrieval-augmented-generation/
- IBM: What is Retrieval-Augmented Generation (RAG)? https://www.ibm.com/topics/retrieval-augmented-generation