大規模言語モデル(LLM)
大規模言語モデル(LLM)とは、大量のテキストやコードから言葉のつながりを学習し、次に続くトークンを予測して文章を生成するAIモデルです。仕組みを知ると、ハルシネーション、文脈窓、プロンプト、データ管理の注意点が理解しやすくなります。
この記事でわかること
- 大規模言語モデル(LLM)の意味
- LLMが文章を生成する基本的な仕組み
- ハルシネーションや文脈窓が起きる理由
- 業務利用で押さえるべき注意点
大規模言語モデル(LLM:Large Language Model)とは、大量のテキストやコードを学習し、入力された文脈に続く言葉を予測して文章を生成するAIモデルです。ChatGPT、Claude、Gemini、Copilotなどの会話型AIや文章生成AIの中核技術として使われています。
LLMは便利ですが、人間のように「事実を理解している」とは限りません。仕組みを知ることで、ハルシネーション、プロンプト、コンテキスト、情報漏洩リスクを現実的に扱いやすくなります。
1. LLMは、言葉のパターンを学習したモデル
LLMは、文章、コード、会話、資料などの大量データから、言葉の並び方や文脈のパターンを学習します。多くの現代的なLLMは、Transformerと呼ばれるアーキテクチャを土台にしています。Transformerは、文中のどの部分に注意を向けるかを計算し、長い文脈の関係を扱いやすくした技術です。
LLMが得意なことは、次のような「言葉を扱う作業」です。
- 文章の下書き
- 要約
- 翻訳
- 分類
- 言い換え
- コード生成
- 質問への回答
- アイデア出し
一方で、LLMは企業データベースや法令DBを常に正確に参照しているわけではありません。外部検索や社内データ連携を使わない限り、回答は学習済みのパターンと入力文脈に基づいて生成されます。
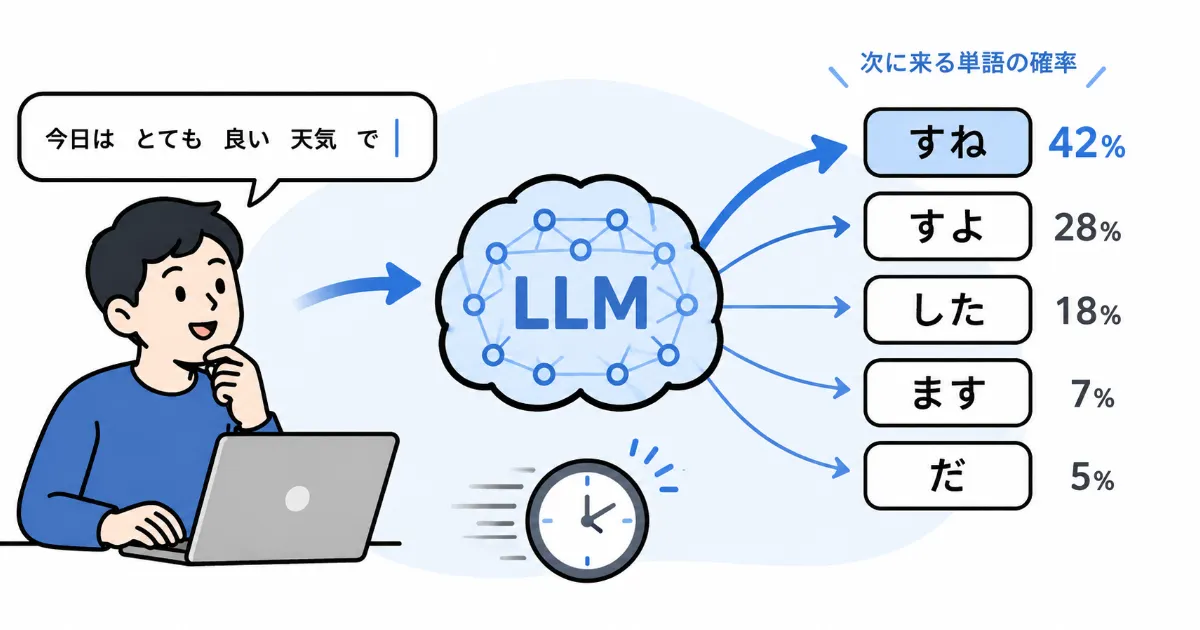
2. 「次のトークン」を予測して文章を作る
LLMの基本的な動きは、次に続くトークンを予測することです。トークンとは、文章を処理するために分けた単位で、単語、文字の一部、記号などが含まれます。
たとえば「請求書の支払期限を」という文脈があると、LLMは次に「確認」「明記」「過ぎた」など、続きそうなトークンの確率を計算します。選ばれたトークンをつなげ、さらに次のトークンを予測することを繰り返して文章を作ります。
この仕組みは非常に強力ですが、同時に限界もあります。
| 仕組み | 便利な点 | 注意点 |
|---|---|---|
| 文脈に続く語を予測する | 自然な文章を素早く作れる | 事実確認をしているとは限らない |
| 大量のデータからパターンを学ぶ | 幅広い話題に対応できる | 古い情報や偏りを含む場合がある |
| 入力文脈を使って回答する | 指示に合わせて出力を変えられる | 指示が曖昧だと推測が増える |
LLMは「もっともらしい文章」を作る力が高いため、正しい文章と誤った文章の見た目の差が小さくなります。
3. ハルシネーションは仕組み上のリスク
LLMは、回答内容が事実として正しいかを常に外部の一次情報と照合しているわけではありません。NIST AI 600-1でも、生成AIは学習データの統計的分布に近い出力を作るため、事実と異なる内容や内部矛盾を出すことがあると整理されています。
その結果、次のようなことが起こります。
- 実在しない文献やURLを出す
- 最新ではない制度を現在の情報として説明する
- 似た会社名や製品名を取り違える
- 社内規程にないルールをもっともらしく補う
- 数値や日付を自然な形で作ってしまう
LLMを使うときは、「文章として自然か」ではなく「根拠に照らして正しいか」を確認します。特に、法務、医療、採用、セキュリティ、顧客提出資料ではファクトチェックが必須です。
4. コンテキストウィンドウには上限がある
LLMは、入力された文章をすべて無限に覚えておけるわけではありません。一度に扱える文脈の範囲には上限があり、これをコンテキストウィンドウと呼びます。
長い資料を読ませるとき、コンテキストウィンドウを超えた部分は切り捨てられたり、要約されたり、参照の優先度が下がったりする場合があります。そのため、「資料を渡したから全部理解したはず」と考えるのは危険です。
長文資料を扱うときは、次のように使うと安定します。
- 対象範囲を章やページで区切る
- 回答の根拠箇所を示させる
- 重要な前提を冒頭で明示する
- 一度に複数の目的を詰め込まない
- 出力後に原文と照合する
5. 入力データが学習に使われるかはサービスごとに違う
LLMそのものの仕組みと、利用中のサービスが入力データをどう扱うかは別の話です。
業務で重要なのは、「このAIモデルは学習するのか」という一般論ではなく、「自分たちが使うサービス・プラン・契約で、入力データが学習利用、保存、監査、外部連携にどう扱われるか」です。
確認すべき項目は次のとおりです。
| 確認項目 | 見るべきこと |
|---|---|
| 学習利用 | 入力・出力・フィードバックがモデル改善に使われるか |
| 保存期間 | 会話履歴やファイルがいつまで残るか |
| 管理権限 | 会社がユーザー、ログ、共有設定を管理できるか |
| 外部連携 | アプリ、プラグイン、社内データ接続の範囲 |
| 契約 | 法人向け条件、DPA、監査ログ、サポート体制 |
この点は、オプトアウトとオプトインやAPI連携の記事とも関係します。
6. LLMは「下書きを速く作る道具」として使う
LLMは、考える材料を増やし、文章作成を速くし、調査の観点を広げる強力な道具です。一方で、事実性、最新性、権限、機密情報、著作権、バイアスの問題を自動的に解決してくれるわけではありません。
業務でLLMを使うときは、「AIが答えたから正しい」ではなく、「AIが作った下書きを、人間が根拠に照らして採用する」という位置づけにします。仕組みを知るほど、AIを怖がりすぎず、過信もしない使い方ができます。
この記事の監修者

石崎 一之進
中小企業診断士
年間50回以上のセミナー・研修に登壇する「Web・ITが得意な中小企業診断士」。単なるツール導入ではなく、経営視点から現場の「業務効率化」と「売れる仕組み」づくりを両輪で伴走支援し、企業の自走を促すDX人材育成に力を入れています。「人材開発支援助成金(事業展開等リスキリング支援コース)」活用で最大75%還元されるAI研修も行っています。詳細はAI研修をご覧ください。
参考文献
- NIST AI 600-1 "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile" https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
- Vaswani et al. "Attention Is All You Need" https://arxiv.org/abs/1706.03762
- Brown et al. "Language Models are Few-Shot Learners" https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html

